ML Training
Training a perceptron in machine learning involves adjusting the weights of the perceptron based on the input data and corresponding outputs to minimize the error in predictions. A perceptron is a type of artificial neural network and a fundamental building block of many machine learning models.
Components of a Perceptron
1: Inputs (x1, x2, ..., xn):
- The features of the data that are fed into the perceptron.
2: Weights (w1, w2, ..., wn):
- Each input has an associated weight that determines its impact on the output.
3: Bias (b):
- A constant added to the weighted sum of the inputs to adjust the output.
4: Activation Function:
- A function (often a step function) that determines the output of the perceptron. For a binary classification task, the perceptron outputs 1 if the weighted sum of the inputs exceeds a threshold and 0 otherwise.
Training Process
The training of a perceptron typically involves the following steps:
1: Initialization:
- Initialize the weights and bias, usually with small random values.
2: Forward Pass:
- Calculate the weighted sum of the inputs and apply the activation function to produce an output.
3: Error Calculation:
- Compute the error, which is the difference between the predicted output and the actual output (label).
4: Weight Update:
- Adjust the weights and bias to minimize the error using a learning rule. The most common rule is the Perceptron Learning Rule:
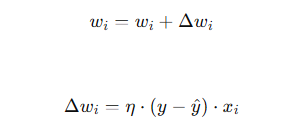
5: Iteration:
- Repeat the forward pass, error calculation, and weight update steps for multiple iterations (epochs) until the error is minimized or another stopping criterion is met.
Example of Training a Perceptron
Let's illustrate the training process with a simple example of binary classification:
Dataset:
Assume we have a dataset with two features (x1, x2) and binary labels (0 or 1).
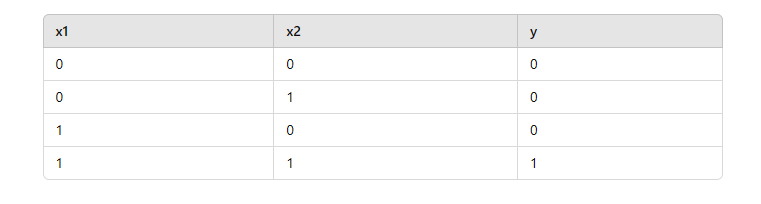
2: Initialization:
- Initialize weights W1 and W2 and bias b to small random values.
Advertisement